Research Statement
My research spans a variety of topics including natural language processing, social media analysis, computational social science, data visualization, and multilinguality.
The Indian sub-continent is socially, linguistically, and culturally rich and offers a variety of problems in linguistics, and the social sciences. Text analyses and social media text analyses from this part of the world are particularly challenging due to the extremely large number of low resource languages people utilize.
How can modern Natural Language Processing (NLP) methods aid these analyses and what can they uncover?
Recent results from produced by me and close collaborators have shown the power of polyglot learning - training a single large scale language model directly on multilingual text. These models have incredible expressive power often producing simple and elegant formulations for a variety of phenomena that occur in the language used by Indian origin populations.
Polyglot learning allowed us to study the 2019 Pulwama Terror attack and its aftermath. At a cursory high level, polyglot skipgram models are capable of splitting apart a multilingual text corpus into precise and accurate monolingual components. This allowed us to produce a highly effective language identification technique tailored for low-resource languages like Romanized Hindi.
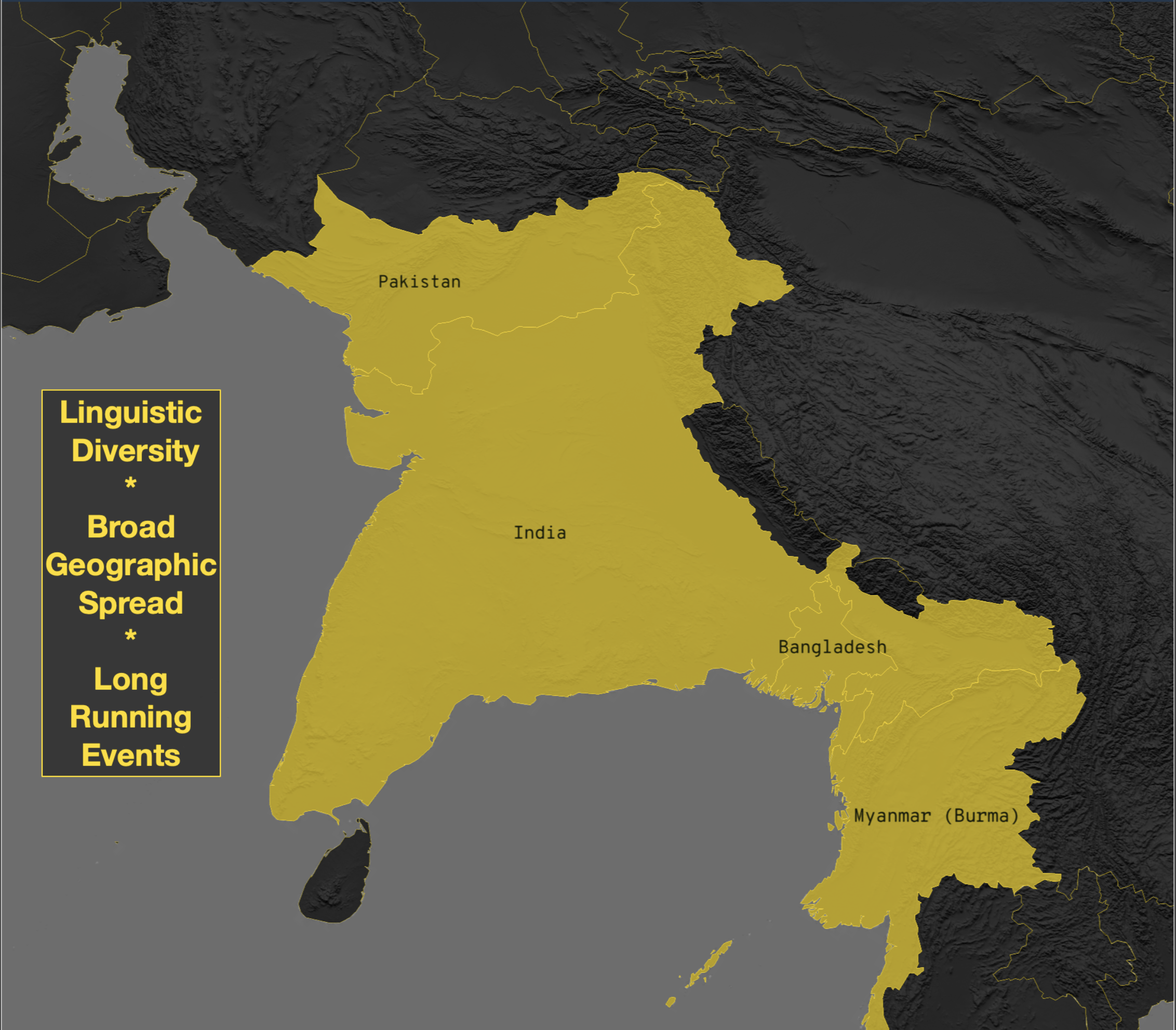
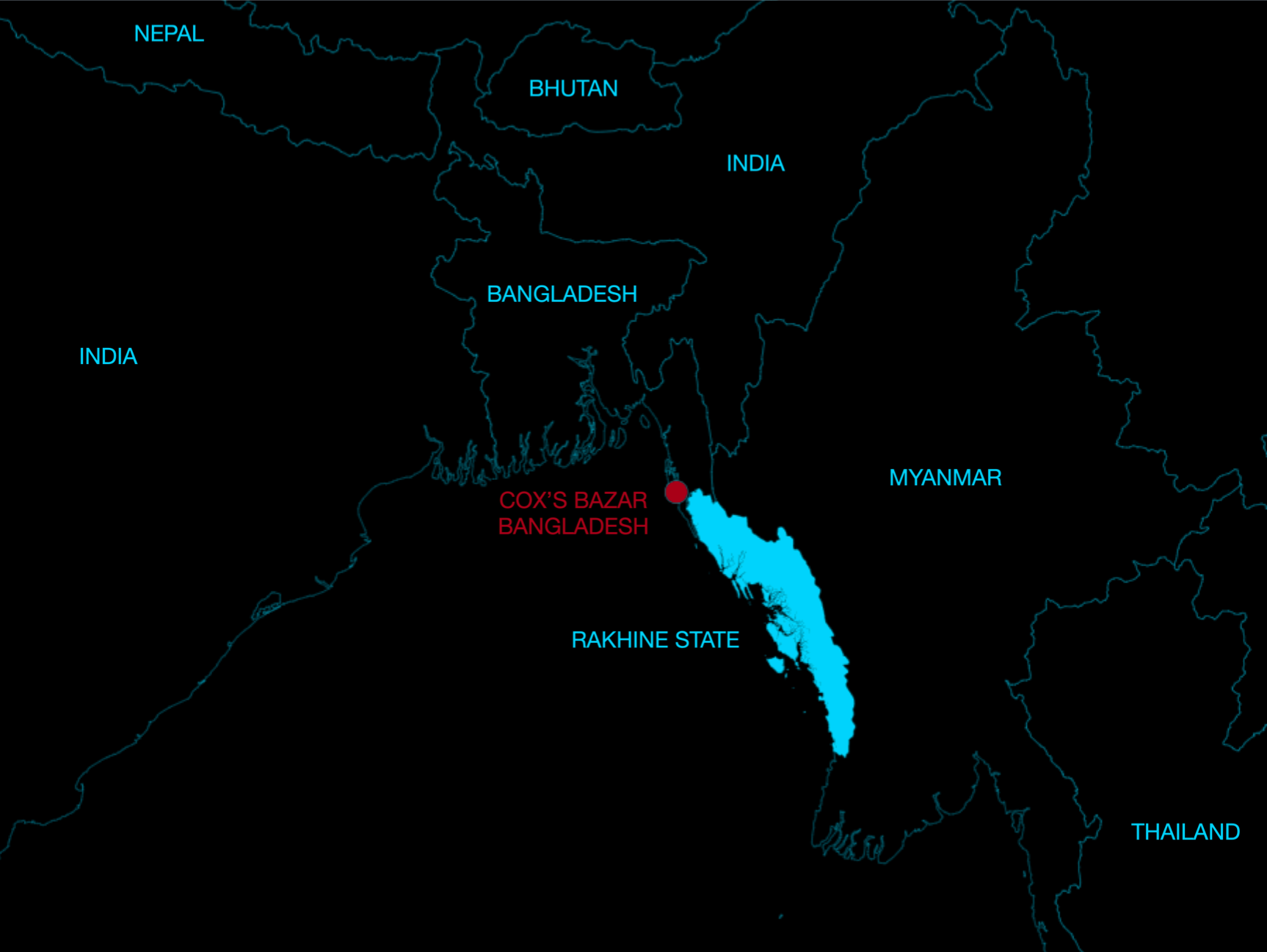
These models were utilized in even harsher conditions in our analysis of the Rohingya crisis.
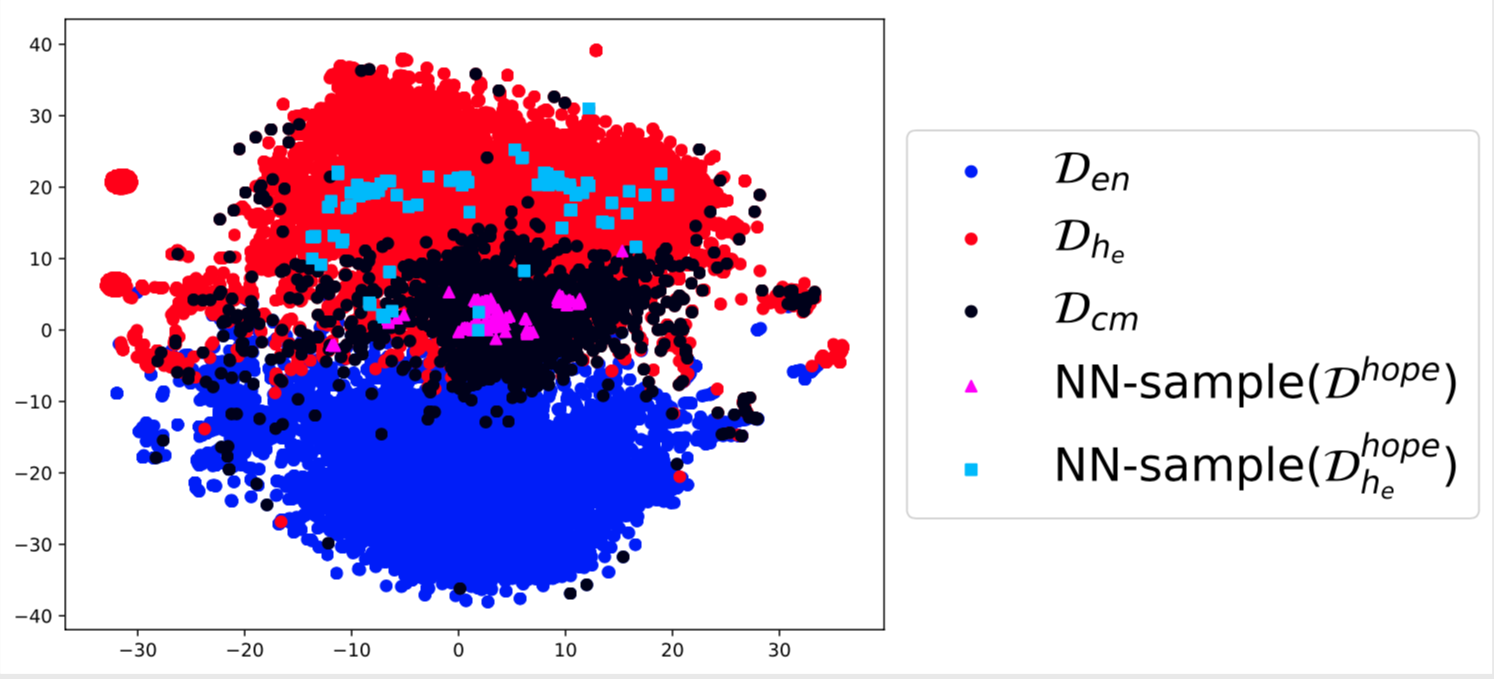
These models also incorporate extremely rich linguistic structure. Simple geometric intuitions allow us to build elegant models of code-switching and utilize these to build cross lingual samplers.
Additional studies have applied large scale language modeling to study elections, polarization, and religion in the Indian subcontinent.
I also work in formal methods, verification, SMT.
Service
- NASA Formal Methods 2020 - Workshop Chair for the Workshop on Formal Methods in Cryptographic Proofs
- Reviewer NeurIPS 2020
- Reviewer DAS 2019